5.5. Огляд алгоритмів та ІС Data Mining
5.5. Огляд алгоритмів та ІС Data Mining
Data Mining — це сукупність багатьох різних методів здобування знань. Вибір методу часто залежить від типу наявних даних і від того, яку інформацію потрібно дістати.
До найпоширеніших методів можна віднести такі:
об’єднання (association; іноді вживають термін affinity, що означає подібність, структурну близькість) — виокремлення структур, що повторюються в часовій послідовності. Цей метод визначає правила, за якими можна встановити, що один набір елементів корелює з іншим. Користуючись ним, аналізують ринковий кошик пакетів продуктів, розробляють каталоги, здійснюють перехресний маркетинг тощо;
аналіз часових рядів (sequence-based analysis, або sequential association) дає змогу відшукувати часові закономірності між даними (трансакціями). Наприклад, можна відповісти на запитання: купівля яких товарів передує купівлі даного виду продукції? Метод застосовується, коли йдеться про аналіз цільових ринків, керування гнучкістю цін або циклом роботи із замовником (Customer Lifecycle Management);
кластеризація (clustering) — групування записів, що мають однакові характеристики, наприклад за близькістю значень полів у БД. Використовується для сегментування ринку та замовників. Можуть залучатися статистичні методи або нейромережі. Кластеризація часто розглядається як перший необхідний крок для подальшого аналізу даних;
класифікація (classification) — віднесення запису до одного із заздалегідь визначених класів, наприклад під час оцінюваня ризиків, пов’язаних із видачею кредиту;
оцінювання (estimation);
нечітка логіка (fuzzy logic);
статистичні методи, що дають змогу знаходити криву, найближче розміщену до набору точок даних;
генетичні алгоритми (genetic algorithms);
фрактальні перетворення (fractal-based transforms);
нейронні мережі (neural networks) — дані пропускаються через шари вузлів, «навчених» розпізнавати ті чи інші структури — використовуються для аналізу переваг і цільових ринків,
а також для приваблювання замовників.
До DM можна віднести ще візуалізацію даних — побудову графічного образу даних, що допомагає у процесі загального аналізу даних вбачати аномалії, структури, тренди. Частково до DM примикають дерева рішень і паралельні бази даних.
DM тісно пов’язана (інтегрована) зі сховищами даних (Data Warehousing, DW), які, можна сказати, забезпечують роботу Data Mining.
Data Mining — міждисциплінарна технологія, що виникла й розвивається на базі досягнень прикладної статистики, розпізнавання образів, методів штучного інтелекту, теорії баз даних тощо (рис. 5.2). Звідси й численні методи та алгоритми, реалізовані в різних дійових системах Data Mining. Багато з таких систем інтегрують у собі відра-
зу кілька підходів. Проте, як правило, у кожній системі присутній певний ключовий компонент, на який робиться головна ставка.
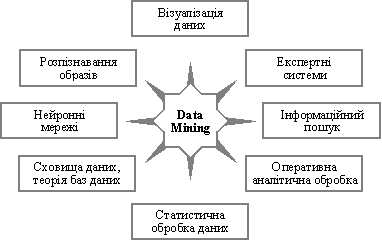
Рис. 5.2. Data Mining — міждисциплінарна галузь
Предметно-орієнтовані аналітичні системи. Такі системи дуже різноманітні. Найширший їх підклас, що набув поширення у сфері дослідження фінансових ринків, дістав назву «технічний аналіз». Він містить кілька десятків методів прогнозування динаміки цін і вибору оптимальної структури інвестиційного портфеля, які ґрунтуються на різних емпіричних моделях динаміки ринку. Зазначені методи, застосовуючи здебільшого нескладний статистичний апарат, максимально враховують специфіку своєї предметної галузі (професійна мова, системи різних індексів тощо). На ринку пропонується багато відповідних програм.
Статистичні пакети. Новітні версії майже всіх відомих статистичних пакетів поряд із традиційними статистичними методами містять також елементи Data Mining. Проте основна увага приділяється в них класичним підходам — кореляційному, регресійному, факторному аналізу та іншим. Недоліком відповідних систем можна вважати вимоги щодо спеціальної підготовки користувача. Існує, однак, і принциповий недолік статистичних пакетів, що обмежує їх застосування в Data Mining: більшість методів, що входять до складу пакетів, спираються на усереднені характеристики вибірки, які в разі дослідження складних життєвих явищ часто є фіктивними. І все ж деякі сучасні пакети пропонують модулі для інтелектуального аналізу. Наприклад, STATISTICA містить модуль Data Miner, що дає змогу будувати дерева рішень, нейронні мережі, виявляти IF THEN правила тощо.
До найпотужніших і найчастіше застосовуваних статистичних пакетів належать SAS (компанія SAS Institute), SPSS (SPSS), STATGRAPICS (Manugistics), STATISTICA, STADIA, Eviews тощо.
Нейронні мережі. Це великий клас систем, архітектура яких певною мірою аналогічна побудові нервової тканини з нейронів. В одній із найпоширеніших архітектур — багатошаровому перцептроні зі зворотним зв’язком помилки, імітується робота нейронів у складі ієрархічної мережі, де кожний нейрон вищого рівня з’єднаний своїми входами з виходами нейронів нижчого шару. На нейрони найнижчого шару подаються значення вхідних параметрів, на підставі яких потрібно приймати якісь рішення, прогнозувати розвиток ситуації тощо. Ці значення розглядаються як сигнали, що передаються в наступний шар, послаблюючи чи підсилюючи його залежно від числових значень (ваг), приписуваних міжнейронним зв’язкам.
У результаті на виході нейрона найвищого шару виробляється деяке значення, що розглядається як відповідь (реакція) всієї мережі на значення вхідних параметрів. Для того щоб мережу можна було використовувати надалі, її потрібно «навчити» на базі здобутих раніше даних, для яких відомі значення вхідних параметрів і правильні відповіді на них. Тренування полягає в доборі ваг міжнейронних зв’язків, що забезпечують найбільшу близькість відповідей мережі до відомих правильних відповідей.
Основним недоліком нейромережної технології є те, що вона потребує дуже великого обсягу навчальної вибірки. Ще один істотний недолік такий: навіть натренована нейронна мережа — це «чорна скринька». Знання, зафіксовані як ваги кількох сотень міжнейронних зв’язків, людина не в змозі проаналізувати й інтерпретувати.
До нейромережних систем належить, скажімо, BrainMaker (CSS), NeuroShell (Ward Systems Group), OWL (HyperLogic).
Системи міркувань на основі аналогічних випадків. Для того щоб зробити деякий прогноз або вибрати правильне рішення, зазначені системи (case based reasoning — CBR) відшукують у минулому близькі аналоги наявної ситуації, вибираючи ті самі відповіді, що були для них правильними. Тому цей метод ще називають методом «найближчого сусіда» (nearest neighbour). Останнім часом набув поширення також термін «memory based reasoning», який акцентує увагу на тому, що рішення приймається на підставі всієї інформації, нагромадженої в пам’яті.
Системи CBR забезпечують добрі результати в найрізноманітніших задачах. Головний їхній недолік полягає в тому, що вони взагалі не створюють будь-яких моделей чи правил, які узагальнюють попередній досвід, а ґрунтуються у виборі рішення на всьому масиві доступних історичних даних. Саме через це не можна встановити, на яких конкретно засадах системи CBR будують свої відповіді.
Інший недолік — певне «свавілля», що його припускаються такі системи, вибираючи міру «близькості», від якої залежить обсяг множини прецедентів, збережуваних у пам’яті з метою досягнення задовільної класифікації або прогнозу.
З-поміж систем CBR назвемо, наприклад, KATE tools (Acknosoft, Франція), Pattern Recognition Workbench (Unica, США).
Дерева рішень (decision trees). Дерева рішень є одним із найпопулярніших підходів до розв’язання задач Data Mining. Вони створюють ієрархічну структуру правил, класифікованих за схемою «ЯКЩО... ТО...» (if-then), яка має вигляд дерева. Для ухвалення рішення про те, до якого класу варто віднести деякий об’єкт (ситуацію, потрібно відповісти на запитання, що містяться у вузлах
цього дерева, починаючи з його кореня. Запитання можуть бути, наприклад, такі: «Значення параметра а більше за x?». Якщо відповідь ствердна, відбувається перехід до правого вузла наступного рівня, якщо заперечна — до лівого вузла. Далі знову ставиться запитання, пов’язане з відповідним вузлом.
Популярність цього підходу зумовлюється наочністю та зро-
зумілістю. Але дерева рішень принципово не здатні знаходити «кращі» (найбільш повні і точні) правила в даних. Вони реалізують принцип послідовного перегляду ознак і збирають фактично уламки наявних закономірностей, створюючи лише ілюзію логічного висновку.
Проте більшість систем діють саме за цим методом. До таких належать, наприклад, See5/З5.0 (RuleQuest, Австралія), Clementine (Integral Solutions, Великобританія), SIPINA (University of Lyon, Франція), IDIS (Information Discovery, США), KnowledgeSeeker (ANGOSS, Канада).
Еволюційне програмування. Сучасний його стан схарактеризуємо, розглянувши систему PolyAnalyst, в якій гіпотези про вигляд залежності цільової змінної від інших змінних формулюються у вигляді програм, що подаються деякою внутрішньою мовою програмування. Процес побудови програм розгортається еволюційно в комплексі програм (на кшталт генетичних алгоритмів). Коли система відшукує програму, що більш-менш задовільно виражає шукану залежність, вона починає вносити до неї невеликі модифікації і добирає серед побудованих дочірніх програм ті, які підвищують точність. У такий спосіб система «вирощує» кілька генетичних ліній програм, що конкурують між собою стосовно точності вираження шуканої залежності. Спеціальний модуль системи PolyAnalyst перекладає знайдені залежності з внутрішньої мови системи зрозумілою користувачеві мовою (математичні формули, таблиці тощо).
Інший напрямок еволюційного програмування пов’язаний із пошуком залежності цільових змінних від решти у формі функцій певного вигляду. Наприклад, один із найбільш вдалих алгоритмів цього типу — метод групового врахування аргументів (МГВА) передбачає відшукання залежності у формі поліномів.
Генетичні алгоритми. Data Mining не є головною сферою застосування генетичних алгоритмів. Їх варто розглядати радше як могутній засіб розв’язання різноманітних комбінаторних задач та задач оптимізації. Проте генетичні алгоритми становлять нині стандартний інструментарій методів Data Mining.
Перший крок під час побудови генетичних алгоритмів — це кодування вихідних логічних закономірностей у базі даних, що їх іменують хромосомами, а весь набір таких закономірностей називають популяцією хромосом. Далі для реалізації концепції вибору вводиться спосіб зіставлення різних хромосом. Популяція обробляється за допомогою процедур репродукції, мінливості (мутацій), генетичної композиції. Ці процедури імітують біологічні процеси. Найважливіші з них такі:
випадкові мутації даних в індивідуальних хромосомах, переходи і рекомбінації генетичного матеріалу, що міститься в індивідуальних батьківських хромосомах, і міграцію генів;
у процесі виконання процедур на кожній стадії еволюції виходять популяції з дедалі досконалішими індивідами.
Генетичні алгоритми зручні тим, що їх легко розпаралелити. Наприклад, можна розбити покоління на кілька груп і працювати з кожною з них незалежно, змінюючи час від часу кілька хромосом. Існують також інші методи розпаралелювання генетичних алгоритмів.
Генетичні алгоритми мають і низку недоліків. Критерій добору хромосом і використовуваних процедур є евристичним і зовсім не гарантує відшукання «найкращого» рішення. Як і в реальному житті, еволюцію може «заклинити» на якій-небудь непродуктивній галузці. І, навпаки, може статися, що безперспективні батьки, яких вилучить з еволюції генетичний алгоритм, будуть здатні породити високоефективного нащадка. Це особливо стає помітним під час розв’язування багатовимірних задач зі складними внутрішніми зв’язками.
Як приклад можна згадати систему GeneHunter фірми Ward Systems Group.
Алгоритми обмеженого перебору. Ці алгоритми обчислюють частоти комбінацій простих логічних подій у підгрупах даних. Приклади простих логічних подій: x = a; x < a; x > a; a < x < b
тощо, де x — деякий параметр, a та b — константи. На підставі аналізу обчислених частот робиться висновок про корисність тієї чи іншої комбінації стосовно встановлення асоціацій у даних, класифікації, прогнозування і т. ін.
Найбільш виразним сучасним представником цього підходу є система WizWhy підприємства WizSoft.
Системи для візуалізації багатовимірних даних. Засоби графічного відображення даних тією чи іншою мірою підтримуються всіма системами Data Mining. Проте дуже значну частку ринку становлять системи, що спеціалізуються винятково на цій функції. Одна з них — програма DataMiner 3D словацької фірми Dimension 5.
У таких системах основна увага сконцентрована на дружньому користувальницькому інтерфейсі, що дає змогу асоціювати з аналізованими показниками різні параметри діаграми розсіювання об’єктів (записів) бази даних. До зазначених параметрів належать колір, форма, орієнтація щодо власної осі, розміри й інші властивості графічних елементів зображення. Крім того, системи візуалізації даних є зручними засобами для масштабування зображень.
Контрольні запитання та завдання
Охарактеризуйте сучасний стан розвитку ІСТ.
У чому полягає сутність технології структурного моделювання (SADT)?
Розкрийте основні ідеї об’єктно-орієнтованого підходу до побудови ІС?
Дайте визначення технології Data Mining.
Чим відрізняється технологія DM від OLAP?
Наведіть основні етапи проведення інтелектуального аналізу даних.
Список додаткової літератури до розділу 2
Волькенштейн М. В. Энтропия и информация. — М.: Наука, 1986. — 192 с.
Глушков В. М. Введение в АСУ. — К.: Тэхника, 1972. — 312 с.
Кальянов Г. Н. CASE структурный системный анализ. — М.: Лори, 1996. — 242 с.
Мамиконов А. Г. Информация и управление. — М.: Наука, 1975. —
184 с.
Марка Д. А., Мак-Гоуэ К. Методология структурного анализа и проектирования: Пер. с англ. — М.: Наука, 1993. — 240 с.
Одинцов Б. Е. Проектирование экономических экспертных систем: Учеб. пособие для студ. вузов, обучающихся по специальности «Информационные системы в экономике» — М.: Компьютер, 1996. — 166 с.
Попов Э. В., Фоминых И. Б., Кисель Е. Б., Шапот М. Д. Статические и динамические экспертные системы: Учеб. пособие для студ. вузов, обучающихся по специальности «Прикладная математика», «Автоматизированные системы обработки информации и управления». — М.: Финансы и статистика, 1996. — 320 с.
Проектирование информационных систем с использованием CASE-технологий: Учеб. пособие / Санкт-Петербургский гос. ун-т водных коммуникаций. — СПб.: СПГУВК, 2000. — 172 с.
Фаулер М. UML в кратком изложении. Применение стандартного языка объектного моделирования. — М.: Мир, 1999.
Черняк Ю. И. Информация и управление. — М.: Наука, 1977.
Шенон К. Работы по теории информации и кибернетике. — М.: ИЛ, 1963. — 829 с.
Экономическая информатика / Под ред. П. В. Конюховского и Д. Н. Колесникова. — Спб.: Питер, 2000. — 560 с.
Экспертные системы: состояние и перспективы: Сб. науч. тр. / АН СССР; Ин-т проблем передачи информации; Под ред. Д. А. Поспелова. — М.: Наука, 1989. — 152 с.
Яглом А. М., Яглом И. М. Вероятность и информация. — М.: Наука, 1973. — 511 с.